Ph.D.Dissertation Defense
Computer Science and Electrical Engineering
University of Maryland, Baltimore County
Schema Free Querying of Semantic Data
Lushan Han
10:00am Friday, 23 May 2014, ITE 325b
Developing interfaces to enable casual, non-expert users to query complex structured data has been the subject of much research over the past forty years. We refer to them as as schema-free query interfaces, since they allow users to freely query data without understanding its schema, knowing how to refer to objects, or mastering the appropriate formal query language. Schema-free query interfaces address fundamental problems in natural language processing, databases and AI to connect users’ conceptual models and machine representations.
However, schema-free query interface systems are faced with three hard problems. First, we still lack a practical interface. Natural Language Interfaces (NLIs) are easy for users but hard for machines. Current NLP techniques are still unreliable in extracting the relational structure from natural language questions. Keyword query interfaces, on the other hand, have limited expressiveness and inherit ambiguity from the natural language terms used as keywords. Second, people express or model the same meaning in many different ways, which can result in the vocabulary and structure mismatches between users’ queries and the machines’ representation. We still rely on ad hoc and labor-intensive approaches to deal with this ‘semantic heterogeneity problem’. Third, the Web has seen increasing amounts of open domain semantic data with heterogeneous or unknown schemas, which challenges traditional NLI systems that require a well-defined schema. Some modern systems gave up the approach of translating the user query into a formal query at the schema level and chose to directly search into the entity network (ABox) for the matchings of the user query. This approach, however, is computationally expensive and has an ad hoc nature.
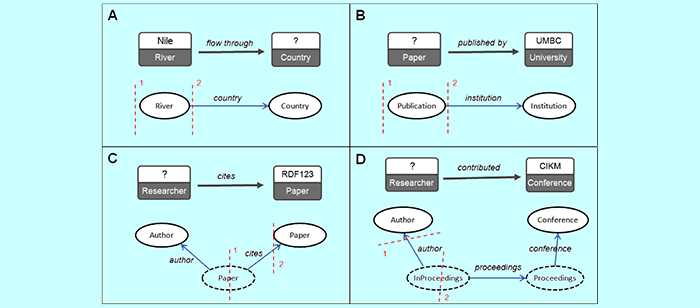
In this thesis, we develop a novel approach to address the three hard problems. We introduce a new schema-free query interface, SFQ interface, in which users explicitly specify the relational structure of the query as a graphical “skeleton” and annotate it with freely chosen words, phrases and entity names. This circumvents the unreliable step of extracting complete relations from natural language queries.
We describe a framework for interpreting these SFQ queries over open domain semantic data that automatically translates them to formal queries. First, we learn a schema statistically from the entity network and represent as a graph, which we call the schema network. Our mapping algorithms run on the schema network rather than the entity network, enhancing scalability. We define the probability of “observing” a path on the schema network. Following it, we create two statistical association models that will be used to carry out disambiguation. Novel mapping algorithms are developed that exploit semantic similarity measures and association measures to address the structure and vocabulary mismatch problems. Our approach is fully computational and requires no special lexicons, mapping rules, domain-specific syntactic or semantic grammars, thesauri or hard-coded semantics.
We evaluate our approach on two large datasets, DBLP+ and DBpedia. We developed DBLP+ by augmenting the DBLP dataset with additional data from CiteSeerX and ArnetMiner. We created 220 SFQ queries on the DBLP+ dataset. For DBpedia, we had three human subjects (who were unfamiliar with DBpedia) translate 33 natural language questions from the 2011 QALD workshop into SFQ queries. We carried out cross-validation on the 220 DBLP+ queries and cross-domain validation on the 99 DBpedia queries in which the parameters tuned for the DBLP+ queries are applied to the DBpedia queries. The evaluation results on the two datasets show that our system has very good efficacy and efficiency.
Committee: Drs. Li Ding (Memect), Tim Finin (chair), Anupam Joshi, Paul McNamee (JHU), Yelena Yesha